Abandono, Reflexión y Seducción como herramienta esencial en Investigación de Mercados.
Las escalas de actitudes presentan problemas de medida que sesgan la información al menos en dos campos: en la propia medición que realizan y en las aplicaciones de cara a una segmentación.
Para mejorar la medida de las actitudes y minimizar el sesgo podemos utilizar las modernas técnicas de Escalas de Máximas Diferencias, herramienta estadística potente, que se aplica a través de los medios actuales de recogida de información (on-line), medotología flexible, fácil de usar y aplicable en contextos multiculturales. Por otro lado si las escalas se utilizan para construir una segmentación, los nuevos modelos de Clustering of Cluster también minimizan el sesgo de las escalas mejorando la precisión en la detección de los segmentos. En síntesis, estas nuevas herramientas tienen un beneficio claro para el investigador: obtener unos mejores resultados, más coherentes, más explicables y que nos sirvan para detectar mejor los problemas y realizar unas mejores recomendaciones de marketing.
En la investigación de mercados es frecuente medir las preferencias o la importancia de los ítems tales como marcas, características de productos, frases publicitarias, etc. La forma más común de medir estas cuestiones es a través de escalas de diferentes tipos. Las más usadas hacen referencia a:
1. La valoración con una escala de puntuación: por ejemplo valorar entre 0 y 10 puntos características tales como la potencia, los efectos secundarios, la toxicidad, etc.
2. Las escalas tipo Likert donde el entrevistado opina en una escala de acuerdo-desacuerdo para cada uno de los ítems (totalmente de acuerdo, de acuerdo en desacuerdo, totalmente en desacuerdo).
3. Ordenar las características o atributos, que sería disponer de un conjunto de características, por ejemplo, potencia, efectos secundarios, toxicidad, etc. y ordenarlos según el criterio que se proponga en el cuestionario. De esta forma el más preferido tendrá un valor de 1, el siguiente más preferido una puntuación de 2 y así sucesivamente.
4. Suma de puntos. Esta forma de medir se basa en que al entrevistado se le dan los atributos o características, por ejemplo potencia, efectos secundarios, toxicidad, etc. y se le pide que reparta 100 puntos entre los atributos con tal de que estos puntos sumen 100 siempre, de esta forma cada uno de los atributos tendrá una valoración teóricamente diferente.
Ningún tipo de medida de escala está exenta de problemas, y seguro que cualquiera de nosotros ha tenido mil y un problemas a la hora de analizar los resultados de una pregunta realizada con estos tipos de escalas, más aún, seguro que hemos tenido problemas a la hora de explicar el porqué de los resultados obtenidos.
Los principales problemas que presentan las escalas tradicionales de uso más común son diversos:
Las escalas de puntuación
Las escalas de puntuación de 0-10, de 1-5, de 1-7, etc., y la escala de Likert con varios grados de acuerdo-desacuerdo, asumen que el entrevistado es capaz de reflejar en esas escalas su opinión y que la muestra entrevistada tiene el mismo parámetro de medida para poder contestar.
Es decir, se asume que todos entienden lo mismo por una puntuación de 7, o que todos entienden lo que es estar en descuerdo, por ejemplo, con la toxicidad de un fármaco. La realidad nos indica que la tendencia a contestar a las escalas puede ser de diferentes maneras y con diferentes significados para cada puntuación, produciéndose sesgos en las respuestas que no podemos controlar.
 Otro problema de este tipo de escalas es la sobrevaloración de las cualidades positivas del ítem y la tendencia a puntuar por encima del valor promedio (en una escala de 0 a 10 puntos raramente alguien valora con un 2 ó con un 3, la mayoría valora por encima de 5 ó 6). Este fenómeno que es un sesgo evidente, se denomina aquiescencia en el campo de las actitudes, pero lo cierto es que por mucho nombre “técnico” que se le quiera dar, es un hecho implícito de esta forma de valorar a través de estas escalas, un hecho que concurre en cualquier individuo, sea prescriptor, sea consumidor.
Otro problema de este tipo de escalas es la sobrevaloración de las cualidades positivas del ítem y la tendencia a puntuar por encima del valor promedio (en una escala de 0 a 10 puntos raramente alguien valora con un 2 ó con un 3, la mayoría valora por encima de 5 ó 6). Este fenómeno que es un sesgo evidente, se denomina aquiescencia en el campo de las actitudes, pero lo cierto es que por mucho nombre “técnico” que se le quiera dar, es un hecho implícito de esta forma de valorar a través de estas escalas, un hecho que concurre en cualquier individuo, sea prescriptor, sea consumidor.
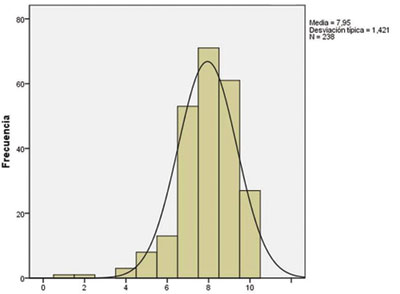
En el gráfico 1 se puede ver una ilustración de este fenómeno. Es un ejemplo real de un estudio de mercado con médicos de Atención Primaria y el ítem preguntado tiene una valoración entre 0 y 10 puntos. Observamos como los valores están concentrados entre 7 y 9 puntos, siendo la media 7,95. En este estudio y en otros similares una batería de este tipo de escalas tiene resultados similares, siendo difícil la discriminación de puntuaciones entre las diversas escalas.
Bien es verdad que en ciertos mercados donde los colectivos son reducidos, como es el caso del sector farmacéutico, hay un fenómeno de aprendizaje que lleva al médico a valorar de forma similar muchos de los atributos que se le presentan.
Ordenación de ítems
Si utilizamos “la ordenación de ítems”, también encontramos problemas. Básicamente tiene dos principales inconvenientes, el primero es que la distancia entre cada uno de los ítems no tiene la misma unidad de medida, es decir, no sabemos cuánto es el tamaño del valor entre el primero y el segundo ítem ordenado y menos entre el tercero y el cuarto. Un segundo problema es que si el número de ítems es grande, el entrevistado pierde la noción de orden y le resulta difícil ordenar por ejemplo 15 atributos.
Suma de puntos
La escala de “suma de puntos”, generalmente 100, tiene su principal inconveniente en el número de ítems, si éstos son muchos el entrevistado pierde fácilmente el marco de referencia para contestar, al igual que sucedía con la escala anterior.
Estos problemas de las escalas implican una clara falta de utilidad para el análisis, para detectar problemas, para sacar conclusiones y mucho menos para tomar acciones de marketing a la luz de sus resultados. Estas escalas nos ponen entre la espada y la pared en múltiples ocasiones y en diferentes mercados por:
1. Falta de discriminación a la hora de elegir qué atributo o atributos son los más importantes para el problema que estamos tratando.
2. Errores no detectados si utilizamos los ítems para introducirlos en un modelo de segmentación, ya que partimos de sesgos que generarán probablemente baja discriminación entre las variables que definan las características de nuestros segmentos.
Pero no tenemos todo perdido. Las “mentes pensantes” de la estadística, ayudadas por los avances de la tecnología informática, trabajan para dar una solución a algunos de los problemas que hemos mencionado anteriormente.
Tenemos varias herramientas que conforman una serie de “Soluciones Avanzadas de Investigación”, concretamente en este artículo hablamos de dos:
• Soluciones Avanzadas de Investigación para los problemas de la falta de discriminación entre atributos: Escalas de Máximas Diferencias.
• Soluciones Avanzadas de Investigación para los problemas del sesgo por falta de discriminación para realizar una segmentación: Clustering of Cluster.
Escalas de Máximas Diferencias
Se trata de hacer escoger al entrevistado entre un conjunto de combinaciones de ítems que pueden ser bloques de 3, 4 o más ítems. La elección se realiza hacia el ítem mejor, más preferido o más importante y el peor, menos preferido o menos importante. Obviamente la elección de la combinación de los ítems que el entrevistado debe escoger, se realiza de acuerdo con los principios del diseño experimental, con lo cual no hace falta que estén presentes todas las combinaciones posibles de pares o tríos de ítems, pudiendo estimarse un valor de importancia para cada uno de ellos, es decir, no son combinados ni por el investigador ni por el cliente.
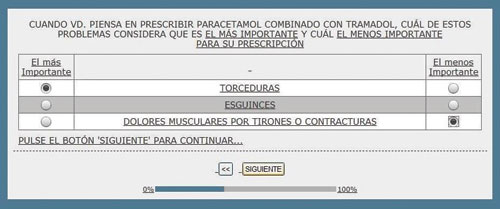
Cada individuo elige entre varias combinaciones (el número de combinaciones obedece también al diseño experimental) y son diferentes de un entrevistado a otro, es decir, que la variabilidad y heterogeneidad de combinaciones es máxima. Por ello es una técnica que empleamos preferentemente por internet (también puede realizarse en CAPI), ya que si se realiza en papel no se recogería la máxima heterogeneidad del diseño y valoración de los individuos.
De esta forma, en Epistéme combinamos la potencia de los modelos estadísticos más modernos con las técnicas de recogida de información ya habituales a través de internet.
Esta forma de preguntar nos permite tratar a todos los ítems de forma igualmente importante o preferente, según sea la orientación de la pregunta.
Las principales ventajas de este método son las siguientes:
• Permite tratar a todos los ítems de forma igualmente importante o preferente, pudiendo ordenar grandes listas de atributos de forma sencilla.
• Fácil respuesta porque sólo consiste en elegir pares de respuestas, la mejor o la peor, la más importante o la menos, de un conjunto de ítems presentados.
• Reduce los sesgos que pueda presentar otro tipo de medida donde hay que decidir una posición numérica, de orden, etc.
• Hay una fuerte discriminación en las respuestas y en los resultados numéricos.
• Es posible realizarlo en cualquier ámbito cultural y país con la consiguiente comparación de los resultados, puesto que en cada país o entorno cultural se utilizan diferentes escalas (0-10, 1-7, 1-5, etc.)
A la hora de analizar y construir conclusiones, lo más importante de este método sería lo siguiente:
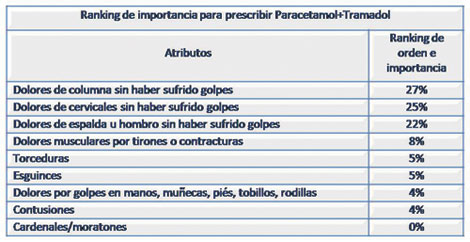
• El resultado para cada ítem es en porcentaje. Obtenemos un RANKING de preferencia de atributos, es decir, obtenemos el orden de atributos y su importancia.
• Tenemos el orden y la importancia de los atributos para cada individuo, lo cual permitirá una segmentación posterior si fuese el objetivo final de la investigación.
• La suma de todos los ítems, como es lógico, es de 100% con lo cual su interpretación es muy sencilla: el ítem que haya obtenido porcentajes más elevados es más importante, valorado o preferido.
• Al entrevistado no se le pregunta por su valoración, sólo tiene que escoger tal y como ya hemos explicado. Evita la respuesta sistemática.
• Los atributos, frases o ítems vienen ya ponderados y no hace falta dar un valor a cada ítem para especular sobre los más o menos importantes como sería el caso de las valoraciones de escalas.
• Los valores en tanto por ciento son para el total de la muestra y para cada entrevistado de forma individual, con lo cual se puede segmentar la muestra en función de los valores resultantes teniendo segmentos de diferentes niveles de importancia o preferencia.
• El resultado de esta técnica nos daría una tabla del siguiente tipo:
Clustering of Cluster
La utilización de escalas de actitudes para generar una segmentación cuenta con el sesgo clásico de la falta de discriminación de los ítems. Los algoritmos clásicos de Cluster Analysis (K-Means, Jerárquico, etc.), pueden utilizar variables basadas en escalas para realizar una segmentación, frecuentemente:
• Bien introducimos directamente las escalas como matriz de entrada de datos.
• Bien introducimos los resultados de un Análisis Factorial (las cargas factoriales) y con ello el Cluster K-Means.
El problema con los resultados es un problema de base, ya que estamos utilizando una información sesgada tal y como mostrábamos en el gráfico nº 1, es decir, contamos con que una parte importante de nuestros encuestados han contestado con aquiescencia, es decir con sesgos hacia uno u otro lado de la escala. El resultado de la segmentación será, pues, sesgado.
El Cluster Analysis convencional (K-Means, Jerárquico, etc.) halla grupos de individuos similares entre sí en función de las variables estudiadas (escalas, en nuestro caso) y que se agrupen en diferentes segmentos.
Los modelos de “Clustering of Cluster” calculan simultáneamente una variedad de soluciones de Clusters y encuentran el mejor consenso para una sola solución, partiendo de grandes grupos de individuos, no de unos pocos individuos como en los clusters tradicionales.
Una de las cuestiones importantes de estos nuevos modelos, es que centran las variables tipo escala para evitar los sesgos comentados y transforman las escalas de tal manera, que trabajan con el entorno de valor que el individuo encuestado realmente ha contestado, sin tener en cuenta el recorrido de la escala inicial (por ejemplo, de 0 a 10 puntos como en el ejemplo del gráfico).
Quedaría pues una escala centrada a cero con valores a la derecha e izquierda, de tal forma, que representen la realidad cercana de las respuestas del encuestado. De esta forma salvamos los sesgos que se generan y obtendremos una segmentación consistente, realista y operativa. También encontramos la posibilidad de tratar los outliers (valores fuera de rango) y la posibilidad de estandarización de las variables si el caso lo requiere.











